dolphinscheduler 环境配置
修改
/etc/profile文件,增加如下环境变量1
2export SEATUNNEL_HOME=/opt/soft/seatunnel
export FLINK_HOME=/opt/soft/flink将seatunnel、flink的包导入到对应的目录下
1
2
3
4[root@flink3 soft]# ls
datax flink python2.7 seatunnel
[root@flink3 soft]# pwd
/opt/soft
seatunnel 环境配置
将需要用到的连接器放置到connector目录下
1
2
3
4[root@flink3 connectors]# ls
connector-console-2.3.6.jar connector-fake-2.3.6.jar connector-kafka-2.3.6.jar plugin-mapping.properties
[root@flink3 connectors]# pwd
/opt/soft/seatunnel/connectors启动flink
1
2
3
4
5[root@flink3 flink]# cd /opt/soft/flink/
[root@flink3 flink]# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host flink3.
Starting taskexecutor daemon on host flink3.安装依赖
1
2
3[root@flink3 ~]# cd /opt/soft/seatunnel/
[root@flink3 seatunnel]# ./bin/install-plugin.sh
Install SeaTunnel connectors plugins, usage version is 2.3.6
使用记录
FakeSource2JdbcSink
从fakesource数据源同步数据到postgresql
1 | env { |
执行结果:
1 | Program execution finished |
kafka2kafka(batch模式)
源数据格式:
1 | "{\n \"CONS_ID\": 612559311320.0,\n \"CONS_NAME\": null,\n \"MP_NO\": \"812410734530050\",\n \"METER_ID\": 4.031410087370826e+16,\n \"T_FACTOR\": 1.0,\n \"ORG_NO\": nul |
源数据中多了很多换行符,转义符,无法进行有效json化,使用seatunnel将字符替换,写入新topic中
1 | env { |
运行后,新topic数据为:
1 | {"CONS_ID":7016732.0,"CONS_NAME":null,"MP_NO":"906405204505770","METER_ID":6.219086100432489e+16,"T_FACTOR":600.0,"ORG_NO":null,"MADE_NO":null,"CONS_NO":"12208475428490","ACCOUNT_FLAG":1 |
批处理模式下,当当前批次的数据处理完成后,flink 任务即结束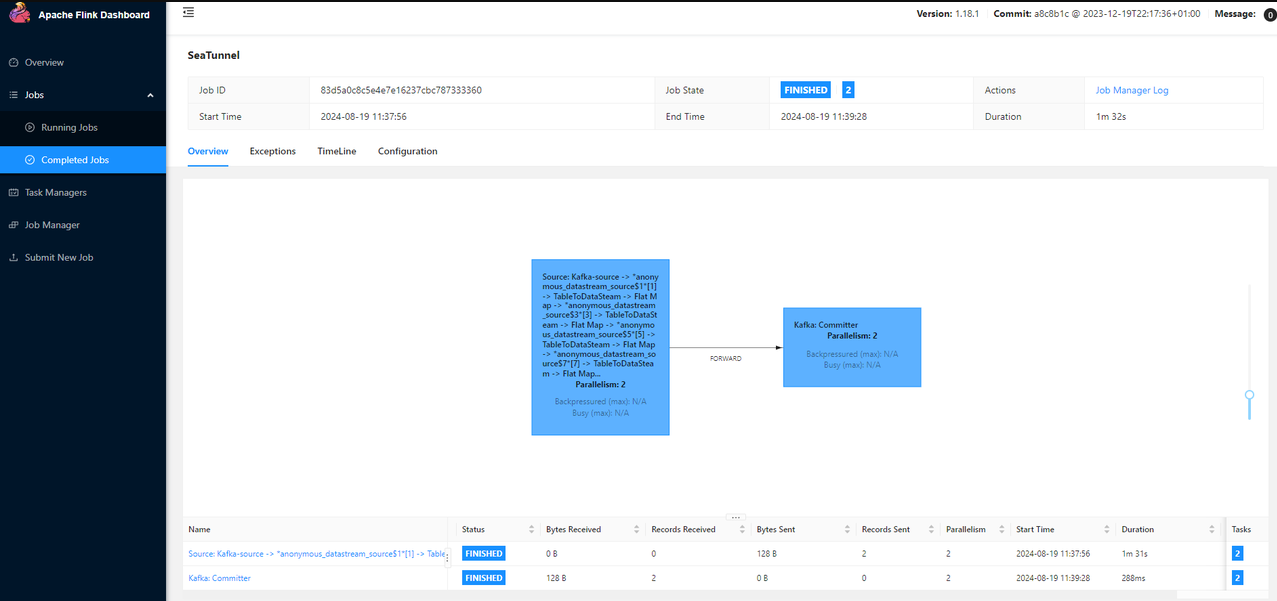
kafka2pg(stream模式)
基于上一个已处理后的topic,将其解析同步到postgres
1 | env { |
运行成功:
1 | dolphinscheduler=> select count(0) from test_table; |
流处理模式下,flink持续监听,即使在dolphinscheduler 停止工作流,也不会对flink 任务产生影响
kafka2kafka + kafka2pg
将kafka2kafka 中的批处理模式改成流处理,然后尝试将kafka2kafka 和kafka2pg放入一个工作流中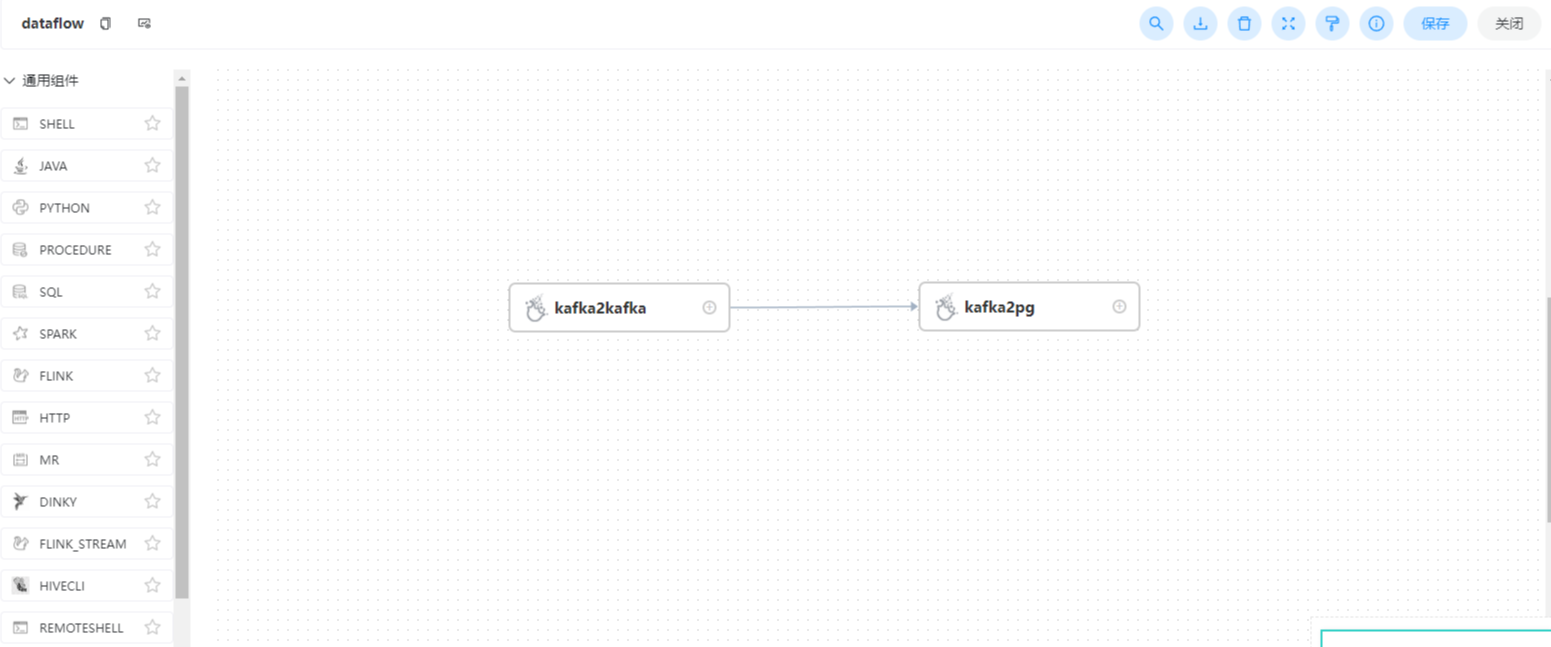
点击运行
由于流处理机制,第一个节点任务始终没有结束,导致kafka2pg这个的节点无法启动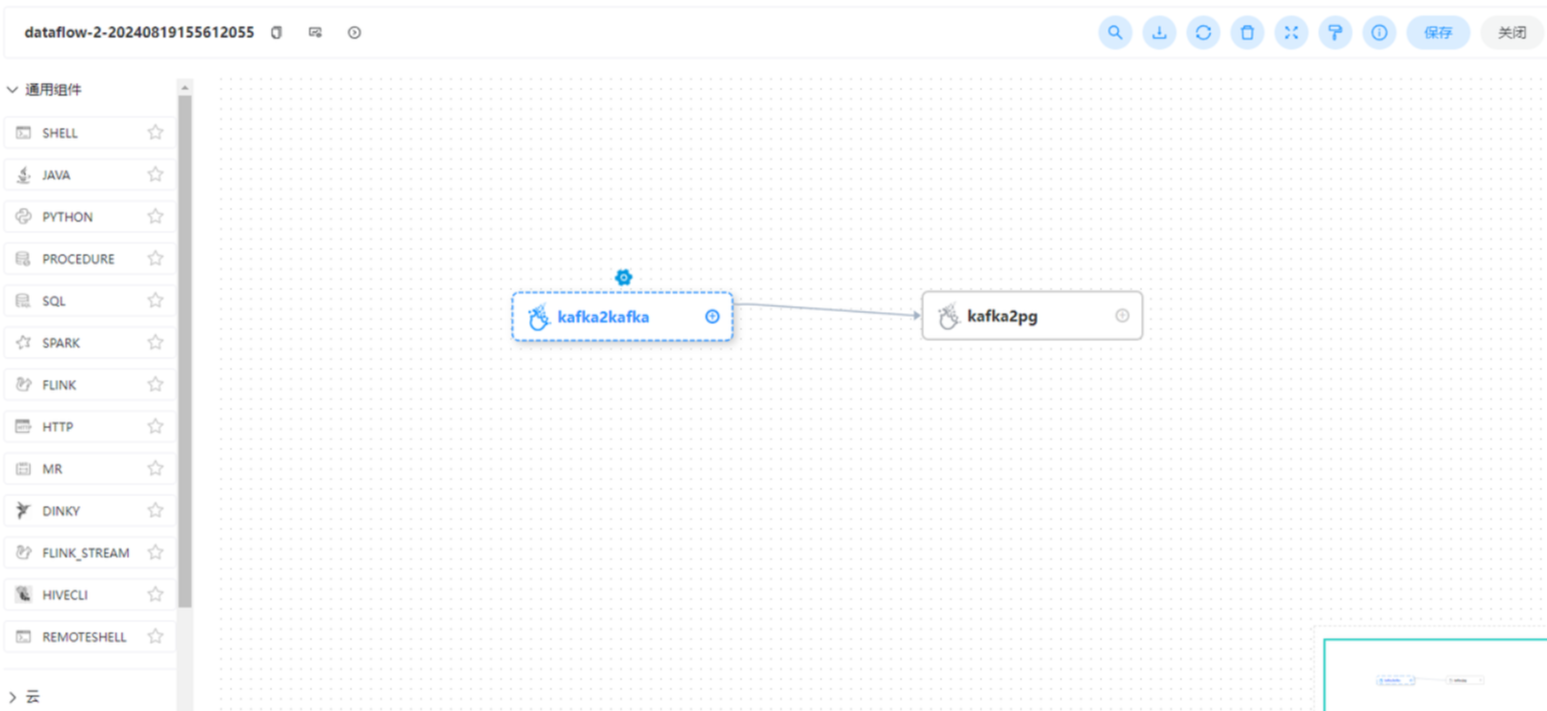
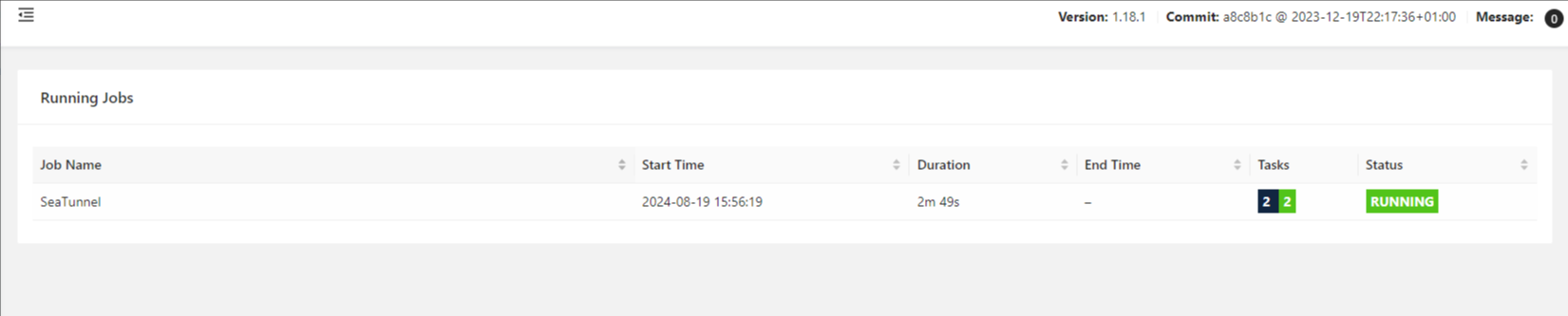
去掉前后关系重新执行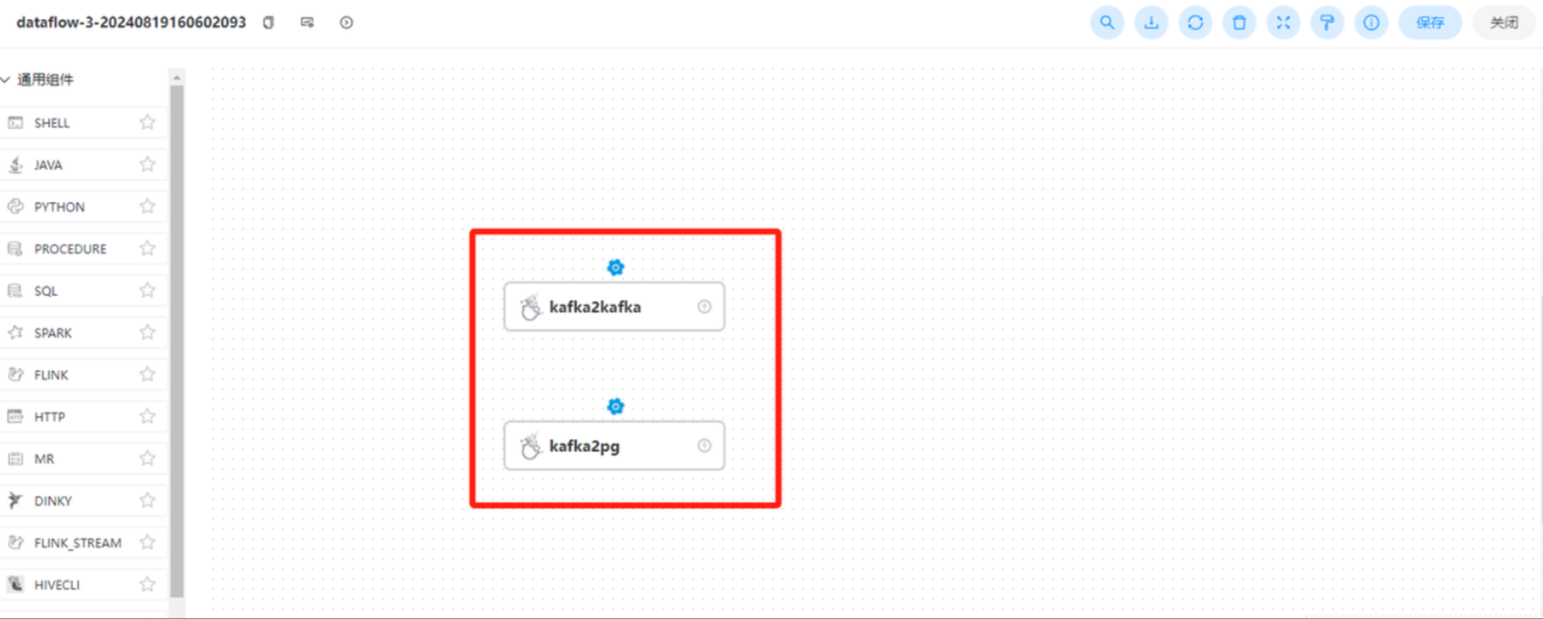
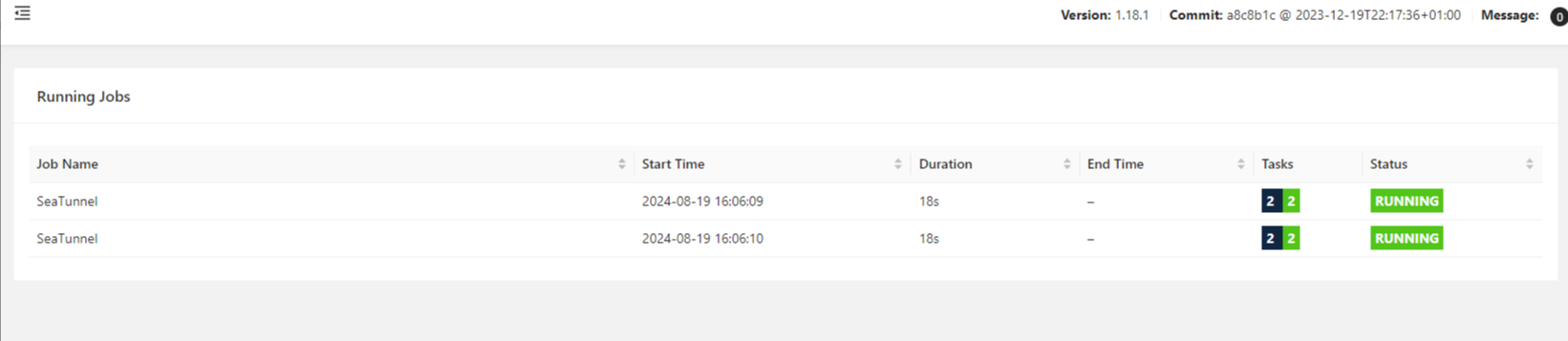
两个任务执行成功
自定义transform
1 | env { |
运行成功:
1 | dolphinscheduler=> select * from test_table where aa is not null; |
多source多sink
1 | env { |
运行结果: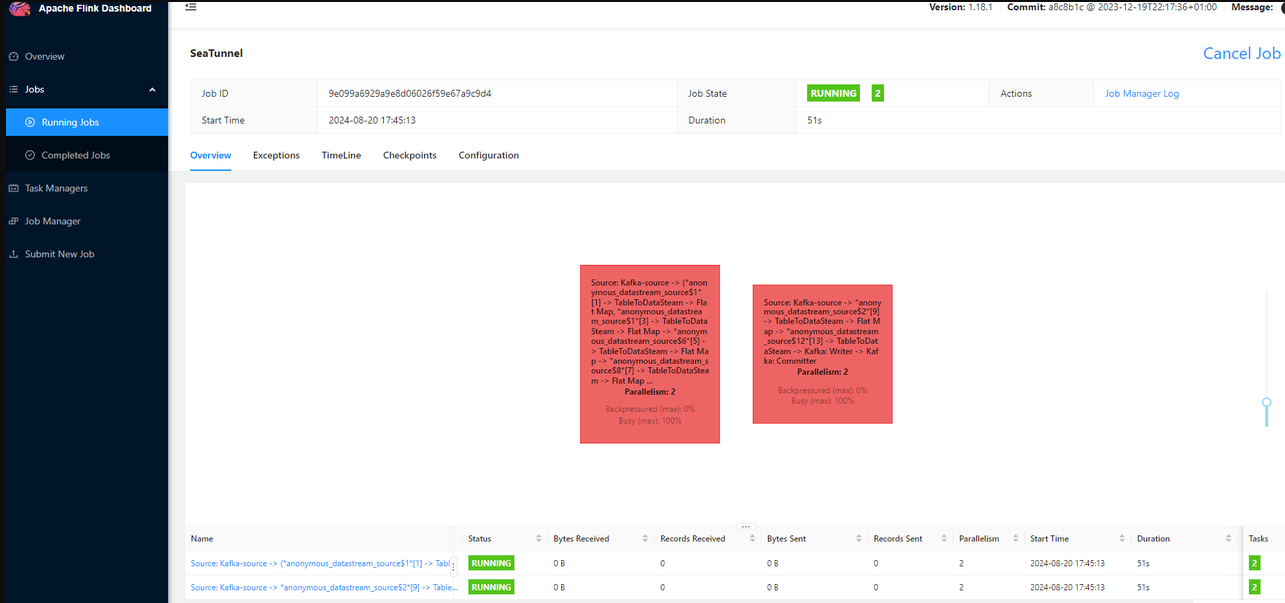
缺陷:多数据源直接不能做连接操作
问题记录
Caused by: java.lang.IllegalStateException: Initialize flink context failed
at org.apache.seatunnel.translation.flink.sink.FlinkSinkWriterContext.getStreamingRuntimeContextForV15(FlinkSinkWriterContext.java:80)高版本flink 不兼容
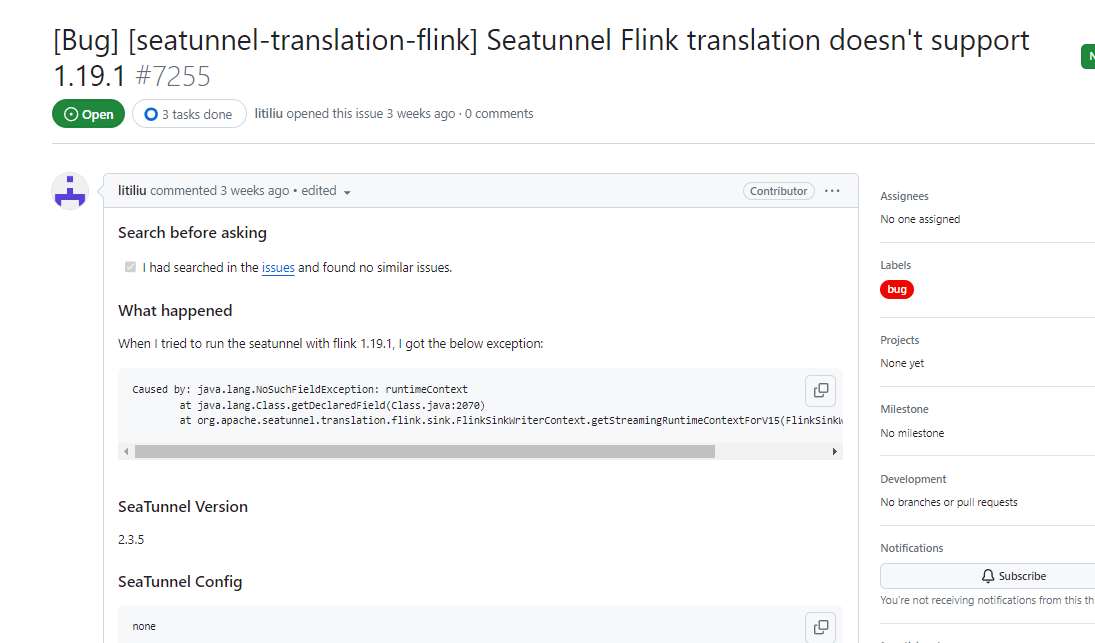
Plugin PluginIdentifier{engineType=’seatunnel’, pluginType=’sink’, pluginName=’jdbc’} not found
connector-jdbc-2.3.6.jar未导入- ClassNotFoundException: org.postgresql.Driver
1
2
3
4[root@flink3 lib]# ls
postgresql-42.3.3.jar
[root@flink3 lib]# pwd
/opt/soft/seatunnel/plugins/jdbc/lib