须知
服务器状态
一个 Raft 集群包含若干个服务器节点;5 个服务器节点是一个典型的例子,这允许整个系统容忍 2 个节点失效。在任何时刻,每一个服务器节点都处于这三个状态之一:领导人、跟随者或者候选人。在通常情况下,系统中只有一个领导人并且其他的节点全部都是跟随者。跟随者都是被动的:他们不会发送任何请求,只是简单的响应来自领导人或者候选人的请求。领导人处理所有的客户端请求(如果一个客户端和跟随者联系,那么跟随者会把请求重定向给领导人)。第三种状态,候选人,是用来在 5.2 节描述的选举新领导人时使用。图 4 展示了这些状态和他们之间的转换关系;这些转换关系会在接下来进行讨论。
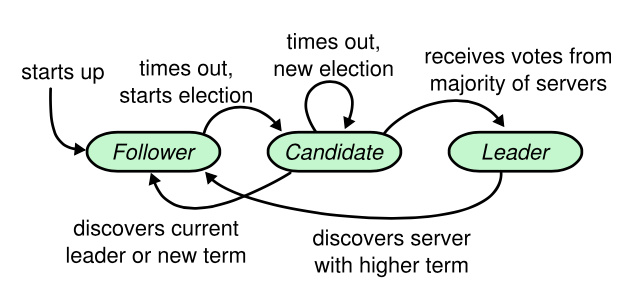
如上图所示:跟随者只响应来自其他服务器的请求。如果跟随者接收不到消息,那么他就会变成候选人并发起一次选举。获得集群中大多数选票的候选人将成为领导人。在一个任期内,领导人一直都会是领导人,直到自己宕机了。
投票条件
在投票者对候选者进行投票,主要针对两个指标判断是否需要投票。
任期
Raft 把时间分割成任意长度的任期。任期用连续的整数标记。每一段任期从一次选举开始,一个或者多个候选人尝试成为领导人。如果一个候选人赢得选举,然后他就在接下来的任期内充当领导人的职责。在某些情况下,一次选举过程会造成选票的瓜分。在这种情况下,这一任期会以没有领导人结束;一个新的任期(和一次新的选举)会很快重新开始。Raft 保证了在一个给定的任期内,最多只有一个领导人。
不同的服务器节点可能多次观察到任期之间的转换,但在某些情况下,一个节点也可能观察不到任何一次选举或者整个任期全程。任期在 Raft 算法中充当逻辑时钟的作用,任期使得服务器可以检测一些过期的信息:比如过期的领导人。每个节点存储一个当前任期号,这一编号在整个时期内单调递增。每当服务器之间通信的时候都会交换当前任期号;如果一个服务器的当前任期号比其他人小,那么他会更新自己的编号到较大的编号值。如果一个候选人或者领导人发现自己的任期号过期了,那么他会立即恢复成跟随者状态。如果一个节点接收到一个包含过期的任期号的请求,那么他会直接拒绝这个请求。
lastLogOpId
yugabyte用 lastLogOpId 记录每个tablet的最后日志条目的id,可对应raft论文中的lastLogIndex概念。投票者使用lastLogOpId判断候选者的日志是否比自己的更新,来决定是否投票给候选者。 通信 Raft 算法中服务器节点之间通信使用远程过程调用(RPCs),并且基本的一致性算法只需要两种类型的 RPCs。请求投票(RequestVote) RPCs 由候选人在选举期间发起,然后附加条目(AppendEntries)RPCs 由领导人发起,用来复制日志和提供一种心跳机制。为了在服务器之间传输快照增加了第三种 RPC。当服务器没有及时的收到 RPC 的响应时,会进行重试, 并且他们能够并行的发起 RPCs 来获得最佳的性能。 在yugabyte中保留了RequestVote请求,使用了UpdateConsensus替代AppendEntries完成心跳机制。
- RequestVote
- UpdateConsensus
选举触发
raft伴随着tablet_peer的启动而启动,当一个 tablet 启动时发生的第一件事是使用Raft协议选择一个 tablet-peer 作为tablet leader。然后让这个tablet leader负责处理面向用户的写入请求。raft启动可见raft启动 当raft集群中的follower长时间收不到来自leader的请求,就会触发超时,从而开始选举。
定时任务
1 每次raft启动时,会创建一个定时任务,启动检测超时。
Status RaftConsensus::Start(const ConsensusBootstrapInfo& info) {
......
failure_detector_ = PeriodicTimer::Create(
peer_proxy_factory_->messenger(),
[w]() {
if (auto consensus = w.lock()) {
consensus->ReportFailureDetected();
}
},
MinimumElectionTimeout());
......
}
void RaftConsensus::ReportFailureDetected() {
......
auto s = raft_pool_token_->SubmitFunc(
std::bind(&RaftConsensus::ReportFailureDetectedTask, shared_from_this()));
......
}
2 当变成为leader时,停止这个超时检测。
Status RaftConsensus::BecomeLeaderUnlocked() {
......
// Disable FD while we are leader.
DisableFailureDetector();
......
}
3 当变成follower时,启动检测。
Status RaftConsensus::BecomeReplicaUnlocked(
......
// FD should be running while we are a follower.
EnableFailureDetector(initial_fd_wait);
......
}
4 当follower连续6个心跳时间未收到leader心跳时,检测任务启动,在ReportFailureDetectedTask函数中循环检测是否存在超时。
void RaftConsensus::ReportFailureDetectedTask() {
......
MonoTime now;
for (;;) {
// Do not start election for an extended period of time if we were recently stepped down.
auto old_value = withhold_election_start_until_.load(std::memory_order_acquire);
if (old_value == MonoTime::Min()) {
break;
}
if (!now.Initialized()) {
now = MonoTime::Now();
}
if (now < old_value) {
VLOG(1) << "Skipping election due to delayed timeout for " << (old_value - now);
return;
}
// If we ever stepped down and then delayed election start did get scheduled, reset that we
// are out of that extra delay mode.
if (withhold_election_start_until_.compare_exchange_weak(
old_value, MonoTime::Min(), std::memory_order_release)) {
break;
}
}
// Start an election.
LOG_WITH_PREFIX(INFO) << "ReportFailDetected: Starting NORMAL_ELECTION...";
Status s = StartElection({ElectionMode::NORMAL_ELECTION});
if (PREDICT_FALSE(!s.ok())) {
LOG_WITH_PREFIX(WARNING) << "Failed to trigger leader election: " << s.ToString();
}
}
超时判断主要靠withholdelection_start_until存储的值与当前时间进行比较。withholdelection_start_until默认为MonoTime::Min()也就是当执行到if (old_value == MonoTime::Min())就break出去开始选举了。特殊情况下,当一个leader变成follower时,会依赖后续比较。
心跳机制
Raft 使用一种心跳机制来避免触发领导人选举。当系统正常运行后,leader周期性的向所有follower发送心跳包(即不包含日志项内容的附加条目(UpdateConsensus) RPCs)来维持自己的权威。如果一个跟随者在一段时间里没有接收到任何消息,也就是选举超时,那么他就会认为系统中没有可用的领导人,并且发起选举以选出新的领导人。 Raft 算法使用随机选举超时时间的方法来确保很少会发生选票瓜分的情况,就算发生也能很快的解决。为了阻止选票起初就被瓜分,选举超时时间是从一个固定的区间(例如 150-300 毫秒)随机选择。
成为leader
当一个peer成为leader,会将所有其他远端peer加入到自己的peer_manager中,然后定期发起心跳。
BecomeLeaderUnlocked
- DisableFailureDetector // 暂停超时检测
- RefreshConsensusQueueAndPeersUnlocked // 更新peer角色信息
- UpdateRaftConfig // 更新配置,若有新的peer,需要加入配置
- NewRemotePeer // 创建远端peer信息
- Init // 远端peer初始化,创建定时器,定期向远端发送心跳
- SignalRequest // 除了定期发送心跳,成为leader后会立马发送一次心跳请求
1 主要看UpdateRaftConfig函数,会生成远端peer信息,写入内存peers_变量中。
void PeerManager::UpdateRaftConfig(const RaftConfigPB& config) {
......
for (const RaftPeerPB& peer_pb : config.peers()) {
......
auto remote_peer = Peer::NewRemotePeer(......);
......
peers_[peer_pb.permanent_uuid()] = std::move(*remote_peer);
}
}
2 远端peer Init时,会创建一个定时器,定时发送心跳信息。
Status Peer::Init() {
......
heartbeater_ = PeriodicTimer::Create(
......
Status s = p->SignalRequest(RequestTriggerMode::kAlwaysSend);
......
......
}
3 SignalRequest,成为leader后会立马发送一次请求,通知所有follower。
void PeerManager::SignalRequest(RequestTriggerMode trigger_mode) {
......
for (auto iter = peers_.begin(); iter != peers_.end();) {
Status s = iter->second->SignalRequest(trigger_mode);
......
}
......
}
成为follower
成为follower后,启动超时检测,关闭自己的PeerManager,清理所有记录的远端peer信息。
BecomeReplicaUnlocked
- EnableFailureDetector // 启动超时检测
- PeerManager::Close() // 关闭PeerManager
- Peer::Close() // 关闭远端peer
- heartbeater_->Stop() // 停止定时心跳
- peers_.clear() // 清理peers_
心跳信息
1 leader发送心跳请求
SignalRequest
- SendNextRequest
- UpdateAsync
- UpdateConsensusAsync
2 follower收到请求,最终暂停超时检测任务,从而保证leader的权威。
UpdateConsensus
- Update
- UpdateReplica
- SnoozeFailureDetector
void RaftConsensus::SnoozeFailureDetector(AllowLogging allow_logging, MonoDelta delta) {
......
if (!delta.Initialized()) {
delta = MinimumElectionTimeout();
}
failure_detector_->Snooze(delta);
}
}
MonoDelta RaftConsensus::MinimumElectionTimeout() const {
int32_t failure_timeout = FLAGS_leader_failure_max_missed_heartbeat_periods *
FLAGS_raft_heartbeat_interval_ms;
return MonoDelta::FromMilliseconds(failure_timeout);
}
leader_failure_max_missed_heartbeat_periods设置为6。也就是follower在6次心跳时间内都没有收到来自leader的请求,就会启动超时检测。 超时检测 有了定时任务以及心跳机制,来看看系统什么会启动定时任务中的超时检测,开始选主。
- 当集群启动时,集群中所有tablet-peer启动后,默认角色都为follower,所以必然收不到来自leader的心跳,然后触发定时任务中的超时检测,开始选举。
- 当一个leader被选举出来后,首先停止自己的超时检测,然后定期向所有的follower发送心跳,使得所有follower暂停心跳检测,从而保持自己的leader地位。
- 而当一个leader故障,无法发送心跳请求。follower在6次心跳时间内都没有收到来自leader的请求,就会启动超时检测,重新开始选主。
选举
预选举
在上面的介绍中,如果一个Follower与其他节点网络隔离,如下图所示:
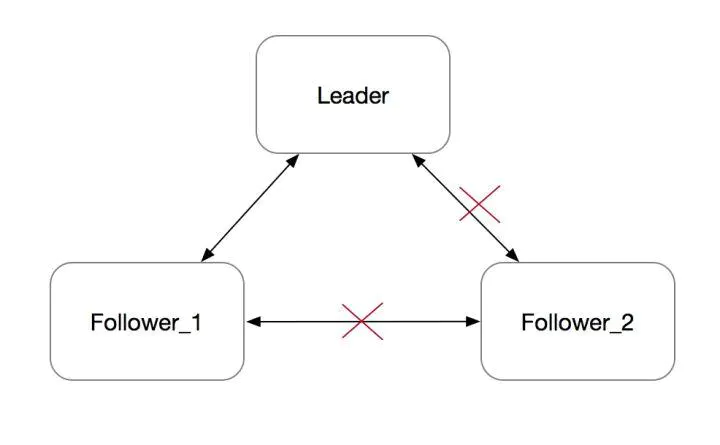
Follower_2在长时间收不收到心跳之后,会发起选举,并转为Candidate。每次发起选举时,会把Term加一。由于网络隔离,它既不会被选成Leader,也不会收到Leader的消息,而是会一直不断地发起选举。Term会不断增大。 一段时间之后,这个节点的Term会非常大。在网络恢复之后,这个节点会把它的Term传播到集群的其他节点,导致其他节点更新自己的term,变为Follower。然后触发重新选主,但这个旧的Follower_2节点由于其日志不是最新,并不会成为Leader。整个集群被这个网络隔离过的旧节点扰乱,显然需要避免的。 为解决这一问题,提出了PreVote概念。在PreVote算法中,Candidate首先要确认自己能赢得集群中大多数节点的投票,这样才会把自己的term增加,然后发起真正的投票。其他投票节点同意发起选举的条件是(同时满足下面两个条件):
- 没有收到有效领导的心跳,至少有一次选举超时。
- Candidate的日志足够新(Term更大,或者Term相同raft index更大)。 PreVote算法解决了网络分区节点在重新加入时,会中断集群的问题。在PreVote算法中,网络分区节点由于无法获得大部分节点的许可,因此无法增加其Term。然后当它重新加入集群时,它仍然无法递增其Term,因为其他服务器将一直收到来自Leader节点的定期心跳信息。一旦该服务器从领导者接收到心跳,它将返回到Follower状态,Term和Leader一致。 yugabyte在代码层面将PreVote这一概念修改为了pre-election。在触发选举后,首先会进行一次pre-election,预选举成功后发起正式选举。
发起投票
选举触发后,会调用Status s = StartElection({ElectionMode::NORMAL_ELECTION}),那我们从StartElection开始。
StartElection
- DoStartElection
- CreateElectionUnlocked
- Run
1 StartElection开始选举。
CHECKED_STATUS StartElection(const LeaderElectionData& data) override {
return DoStartElection(data, PreElected::kFalse);
}
DoStartElection的参数为PreElected::kFalse代表未预选举过,所以第一次的选举是一次预选举过程。
2 DoStartElection创建选举实例并运行。
Status RaftConsensus::DoStartElection(const LeaderElectionData& data, PreElected preelected) {
...... 判断是否为预选举
auto preelection = ANNOTATE_UNPROTECTED_READ(FLAGS_use_preelection) && !preelected &&
disable_pre_elections_until_ < CoarseMonoClock::now();
const char* election_name = preelection ? "pre-election" : "election";
......
election = VERIFY_RESULT(CreateElectionUnlocked(data, timeout, PreElection(preelection)));
......
if (election) {
election->Run();
}
......
}
3 CreateElectionUnlocked创建选举实例,给自己投票。
Result<LeaderElectionPtr> RaftConsensus::CreateElectionUnlocked(......) {
...... 预选举不需要增加term
if (preelection) {
new_term = state_->GetCurrentTermUnlocked() + 1;
} else {
// Increment the term.
RETURN_NOT_OK(IncrementTermUnlocked());
new_term = state_->GetCurrentTermUnlocked();
}
...... 给自己投票
RETURN_NOT_OK(counter->RegisterVote(state_->GetPeerUuid(), ElectionVote::kGranted, &duplicate));
...... 创建实例
LeaderElectionPtr result(new LeaderElection(......));
......
}
4 Run运行实例,向其他tablet_peer发送选举投票请求。
void LeaderElection::Run() {
......
for (const std::string& voter_uuid : voting_follower_uuids_) {
......
state->proxy->RequestConsensusVoteAsync(
&state->request, &state->response, &state->rpc,
std::bind(&LeaderElection::VoteResponseRpcCallback, this, voter_uuid, retained_self));
......
......
}
投票
tablet_peer收到投票请求后,根据term和LastLogOpId的比较,决定是否投票。
- RequestConsensusVote
- RequestVote
- RequestVoteRespondLeaderIsAlive // leader仍存活
- RequestVoteRespondInvalidTerm // 候选者的term比当前投票者的小
- RequestVoteRespondVoteAlreadyGranted // 已为此候选者投过票
- RequestVoteRespondAlreadyVotedForOther // 为这个term的其他候选者投了票
- HandleTermAdvanceUnlocked // 候选者的term比当前投票者的大
- RequestVoteRespondLastOpIdTooOld // 候选者LastLogOpId比当前投票者的小
- FillVoteResponseVoteGranted // 填充预选举请求回复
- RequestVoteRespondVoteGranted // 填充选举请求回复
1 RequestVoteRespondLeaderIsAlive leader仍存活,拒绝投票。
Status RaftConsensus::RequestVoteRespondLeaderIsAlive(const VoteRequestPB* request,
VoteResponsePB* response) {
FillVoteResponseVoteDenied(ConsensusErrorPB::LEADER_IS_ALIVE, response);
......
return Status::OK();
}
2 RequestVoteRespondInvalidTerm 候选者的term比当前投票者的小,拒绝投票。
Status RaftConsensus::RequestVoteRespondInvalidTerm(const VoteRequestPB* request,
VoteResponsePB* response) {
......
RequestVoteRespondVoteDenied(ConsensusErrorPB::INVALID_TERM, message_suffix, *request, response);
return Status::OK();
}
3 RequestVoteRespondVoteAlreadyGranted 已投过票,直接回复。
Status RaftConsensus::RequestVoteRespondVoteAlreadyGranted(const VoteRequestPB* request,
VoteResponsePB* response) {
FillVoteResponseVoteGranted(*request, response);
......
return Status::OK();
}
4 HandleTermAdvanceUnlocked当候选者的term比投票者的大时,设置投票者的term为候选者的term,准备为其投票。
Status RaftConsensus::HandleTermAdvanceUnlocked(ConsensusTerm new_term) {
...... 若投票者为leader,而候选者的term比它大,则将其变成follower
if (state_->GetActiveRoleUnlocked() == RaftPeerPB::LEADER) {
LOG_WITH_PREFIX(INFO) << "Stepping down as leader of term "
<< state_->GetCurrentTermUnlocked()
<< " since new term is " << new_term;
RETURN_NOT_OK(BecomeReplicaUnlocked(std::string()));
}
LOG_WITH_PREFIX(INFO) << "Advancing to term " << new_term;
RETURN_NOT_OK(state_->SetCurrentTermUnlocked(new_term));
term_metric_->set_value(new_term);
return Status::OK();
}
5 RequestVoteRespondLastOpIdTooOld 候选者LastLogOpId比当前投票者的小,拒绝投票。
Status RaftConsensus::RequestVoteRespondLastOpIdTooOld(......) {
......
RequestVoteRespondVoteDenied(
ConsensusErrorPB::LAST_OPID_TOO_OLD, message_suffix, *request, response);
return Status::OK();
}
6 FillVoteResponseVoteGranted响应预选举投票。
void RaftConsensus::FillVoteResponseVoteGranted(
const VoteRequestPB& request, VoteResponsePB* response) {
response->set_responder_term(request.candidate_term());
response->set_vote_granted(true);
}
7 RequestVoteRespondVoteGranted响应选举投票。
Status RaftConsensus::RequestVoteRespondVoteGranted(const VoteRequestPB* request,
VoteResponsePB* response) {
...... 满足投票条件后,先暂停自己的选举触发器,避免重复选举
MonoDelta additional_backoff = LeaderElectionExpBackoffDeltaUnlocked();
SnoozeFailureDetector(ALLOW_LOGGING, additional_backoff);
// Persist our vote to disk.
RETURN_NOT_OK(state_->SetVotedForCurrentTermUnlocked(request->candidate_uuid()));
// 填充投票回复
FillVoteResponseVoteGranted(*request, response);
// 再暂停一次,给候选者足够的时间成为leader. 避免因持久化投票信息到磁盘延迟太高导致触发选举
SnoozeFailureDetector(DO_NOT_LOG, additional_backoff);
......
return Status::OK();
}
统计选票
候选者收到投票者的投票回复后,开始统计处理。
VoteResponseRpcCallback
- RecordVoteUnlocked
- RegisterVote // 记录投票情况
- HandleVoteGrantedUnlocked // 处理投票赞成回复
- HandleVoteDeniedUnlocked // 处理投票拒绝回复
- CheckForDecision // 统计选票,并调用选举回调函数。
- GetDecision // 统计选票
- decision_callback_ // 选举回调,这里的回调函数初始化为了ElectionCallback
1 RegisterVote 记录对应的tablet_peer的投票情况
Status VoteCounter::RegisterVote(......) {
......
// This is a valid vote, so store it.
InsertOrDie(&votes_, voter_uuid, vote);
switch (vote) {
case ElectionVote::kGranted:
++yes_votes_;
break;
case ElectionVote::kDenied:
++no_votes_;
case ElectionVote::kUnknown:
return STATUS_FORMAT(InvalidArgument, "Invalid vote: $0", vote);
}
......
}
2 HandleVoteGrantedUnlocked 处理投票赞成回复
void LeaderElection::HandleVoteGrantedUnlocked(......) {
......
RecordVoteUnlocked(voter_uuid, ElectionVote::kGranted);
}
3 HandleVoteDeniedUnlocked 处理投票拒绝回复
void LeaderElection::HandleVoteDeniedUnlocked(......) {
......
RecordVoteUnlocked(voter_uuid, ElectionVote::kDenied);
}
4 CheckForDecision统计选票并触发选举回调函数。
void LeaderElection::CheckForDecision() {
......
auto decision = vote_counter_->GetDecision(); // 通过这个函数统计最终的得票情况
......
// 选票完成,设置to_respond为ture
if (result_.decided() && !has_responded_) {
has_responded_ = true;
to_respond = true;
}
......
// 触发选举回调
if (to_respond) {
decision_callback_(result_);
}
}
5 GetDecision统计选票,决定候选者是否选举成功。
ElectionVote VoteCounter::GetDecision() const {
if (yes_votes_ >= majority_size_) { // 支持投票的占大多数
return ElectionVote::kGranted;
}
if (no_votes_ > num_voters_ - majority_size_) { // 支持投票的未能占大多数
return ElectionVote::kDenied;
}
return ElectionVote::kUnknown;
}
6 decisioncallback在LeaderElection创建时被初始化为ElectionCallback
Result<LeaderElectionPtr> RaftConsensus::CreateElectionUnlocked(
......
LeaderElectionPtr result(new LeaderElection(
......
std::bind(&RaftConsensus::ElectionCallback, shared_from_this(), data, _1)));
......
}
完成选举
在ElectionCallback函数中完成最后的选举步骤。
ElectionCallback
- DoElectionCallback
- SnoozeFailureDetector // 无论选举成功或失败,先暂停本身的超时检测
- NotifyOriginatorAboutLostElection // 通知发起者选举失败,重置它的超时时间
- LeaderElectionLost // 收到请求
- ElectionLostByProtege // 重置超时时间
- DoStartElection // 选举成功,但因为是预选举,所以发起正式选举
- BecomeLeaderUnlocked // 选举成功,成为leader
1 SnoozeFailureDetector 无论选举成功或失败,先暂停本身的超时检测 2 NotifyOriginatorAboutLostElection 通知发起者选举失败
void RaftConsensus::NotifyOriginatorAboutLostElection(......) {
......
proxy->LeaderElectionLostAsync(......);
......
}
3 LeaderElectionLost收到请求,转到ElectionLostByProtege处理 4 ElectionLostByProtege重置超时时间,若仍没有leader,继续发起选举。
Status RaftConsensus::ElectionLostByProtege(......) {
......
auto start_election = false;
{
......
withhold_election_start_until_.store(MonoTime::Min(), std::memory_order_relaxed);
election_lost_by_protege_at_ = MonoTime::Now();
start_election = !state_->HasLeaderUnlocked();
}
}
if (start_election) {
return StartElection({ElectionMode::NORMAL_ELECTION});
}
......
}
5 DoStartElection 选举成功,但因为是预选举,所以发起正式选举。
DoStartElection(data, PreElected::kTrue) // PreElected参数为true,代表已预选举
6 BecomeLeaderUnlocked,赢得选举,变成leader,开始向其他follower周期性发送心跳信息。
Status RaftConsensus::BecomeLeaderUnlocked() {
......
peer_manager_->SignalRequest(RequestTriggerMode::kNonEmptyOnly);
......
}